独立翻译自:How to Build Your Own Blockchain Part 4.1 — Bitcoin Proof of Work Difficulty Explained
如果您想知道为什么这是第4.1部分而不是第4部分,以及为什么我不讨论继续构建本地jbc,那是因为在较低的层次上解释比特币的工作困难证明需要大量篇幅。所以不像这个标题说的,这篇文章在第4部分不是如何建立一个区块链。它是关于现有的区块链是如何构建。
我在这个第4篇文章的主要目标是有一个关于比特币的部分,下一个是关于Ethereum的部分,最后讨论jbc将如何运行和验证工作量证明。在写完第1部分的全部内容来解释比特币的PoW难度之后,它不适合放在一个单独的部分中。人们,包括我在内,在阅读一篇冗长的文章时,往往会感到无聊而无法完成。
因此,第4.1部分将介绍比特币的PoW难度计算。第4.2部分将通过以太坊的工作量证明来计算。然后第4.3部分将是我决定我想要的jbc PoW如何做以及做时间计算来看看挖掘将花费多长时间。
本文分为以下几个部分:
- Calculate Target from Bits//从位计算目标
- Determining if a Hash is less than the Target//确定哈希是否小于目标
- Calculating Difficulty//计算难度
- How and when block difficulty is updated//如何以及何时更新块难度
- Full code//完整代码
- Final Questions//最后的问题
长话短说
难度的总称是指一个节点需要做多少工作才能找到比target小的hash值。在一个块中有一个值是关于难度的——它就是bits。为了计算散列转换为十六进制值时必须小于target的值,我们使用bits字段并通过一个返回target的方程运行它。然后,我们使用target来计算difficulty,其中difficulty只是一个数字,人类可以通过这个数字来理解该块的工作证明有多困难。
如果您继续阅读,我将介绍区块链如何确定挖掘块的散列需要小于什么样的target数才能有效,以及如何计算该taget值
从Bits计算Target值
为了完成比特币的PoW,我需要使用实际块上的值并解释其计算,这样读者就可以自己验证所有这些代码。首先,我要取一个随机的块号然后用它进行计算。
>>>import random
>>> random.randint(0, 493928)
111388
块号11138 就是它! 时间追溯到2011年3月.
我们将使用块中的bits和difficulty值以及hash来分配变量,这样我们可以在最后测试它的有效性。
>>> bits = '453062093'
>>> difficulty = float('55,589.52'.replace(',',''))
>>> block_hash = '00000000000019c6573a179d385f6b15f4b0645764c4960ee02b33a3c7117d1e'
下一部分将展示如何从bits字段到target。至少有两种不同的方法可以做到这一点—第一种涉及字符串操作和字符串到整数的转换,另一种使用位操作
对于第一个字符串操作部分,我们将位字符串转换为整数,然后转换为十六进制字符串。hex_bits字符串的前两个字符在一个变量中,我称之为shift,其余六个称为value。然后,我们在整数方程中使用这些值来计算target的整数值,我们可以将其转换为十六进制字符串,看看它有多漂亮!
请注意,target和hex(target)后面的L只是Python告诉您,numbexr太长,不能作为int存储,它是存储为long。
>>> hex_bits = hex(int(bits))
>>> hex_bits
'0x1b012dcd'
>>> shift = '0x%s' % hex_bits[2:4]
>>> shift
'0x1b'
>>> shift_int = int(exponent, 16)
27
>>> value = '0x%s' % hex_bits[4:]
>>> value
'0x012dcd'
>>> value_int = int(coefficient, 16)
77261
>>> target = value_int * 2 ** (8 * (shift_int - 3))
>>> target
484975157177710342494716926626447514974484083994735770500857856L
>>> hex_target = hex(target)
>>> hex_target
'0x12dcd000000000000000000000000000000000000000000000000L'
当我们像上面那样分割字符串来计算target值时,这看起来有点假。当查看c++ bitcoin实现时,它显示了使用bits计算target的另一种更技术的主要方法。但这里是Python实现。
我将逐行打印这里的值,以便更好地显示发生了什么。在阅读之前需要知道的一件事是十六进制字符串中的一个字符表示4位。因此,当我们用bits >> 24将位变量移位24位时,有效地删除了十六进制字符串的最后6个字符,只留下前两个。为了得到值变量,我们使用位和运算符&取得最后23位的值。这23位通常是十六进制字符串的最后6个字符(由0x7fffff中的位数定义),
现在,8 * (shift - 3)的值决定了我们要移位多少位。在这种情况下,它被确定为192位。如果我们把192除以4,我们就会得到target数的十六进制字符串表示的值后面的零字符个数。你会看到它是48个0。另一件让人困惑的事情是value << y和value * 2**y是一样的。这就是方程之间的关系。
>>> bits = '453062093'
>>> hex(int(bits))
'0x1b012dcd'
>>> shift = bits >> 24
>>> shift
27
>>> hex(shift)
'0x1b'
>>> value = bits & 0x007fffff
>>> hex(value)
'0x12dcd'
>>> 8 * (shift - 3)
192
>>> 192 / 4 #each character in a hex string represents 4 bits
48
>>> value <<= 8 * (shift - 3)
>>> hex(value)
'0x12dcd000000000000000000000000000000000000000000000000L'
>>> hex(value).count('0') - 1 #don't count the leading zero
48
完整的函数版本只有几行。
>>> def get_target_from_bits(bits):
... shift = bits >> 24
... value = bits & 0x007fffff
... value <<= 8 * (shift - 3)
... return value
...
>>> target = def get_target_from_bits(int(bits))
>>> hex(target)
'0x12dcd000000000000000000000000000000000000000000000000L'
太好了。如果您查看上面的字符串操作代码,会发现它比上面的函数更令人困惑,而且还有许多额外的行。通过这两种方法来真正理解它的含义是很好的,但是要坚持使用简单的方法。前进吧。
确定hash是否小于target
通常,有两种简单的方法可以查看块的哈希是否对于target有效。第一种方法是使用完整的,64个字符,256位,十六进制字符串并比较它们。这很有用,因为我们可以很容易地看到这一点。为了说明这种情况,我们将用0填充hex_target来填满所有64个字符。
>>> hex_target = hex(target)
>>> len(hex_target)
56
>>> len(hex_target[2:-1]) #[2:-1] removes the leading '0x' and ending 'L'
53
>>> num_padded_zeros = 64 - hex_target_len
>>> num_padded_zeros
11
>>> padded_hex_target = "0x%s%sL" % ('0' * (64-num_padded_zeros), hex_target[2:-1])
>>> padded_hex_target
'0x0000000000012dcd000000000000000000000000000000000000000000000000L'
最后,我们希望验证块的散列是否小于target。而且,因为字符串可以被认为小于或大于,我们就这么做吧。
>>> len(block_hash)
64
>>> padded_block_hash = '0x%sL' % block_hash
>>> padded_block_hash
0x00000000000019c6573a179d385f6b15f4b0645764c4960ee02b33a3c7117d1eL
>>> padded_hex_target
0x0000000000012dcd000000000000000000000000000000000000000000000000L
>>> assert padded_block_hash < padded_hex_target
>>>
在这种情况下,您将看到十六进制target大于块的hash。比较哪个字符串更大就像<或>一样简单。如果您想知道Python如何确定`'f' > '1'`之类的字符,请参见下面的问题。
另一种确认方法是对两个值都使用整数。但是你会看到,很难,如果不是不可能的话,观察哪个值更大,一个值比另一个大多少。
>>> block_hash_int = int(block_hash, 16)
>>> block_hash_int
41418456048005639864974238890271849696605172030151526454492446L
>>> target
484975157177710342494716926626447514974484083994735770500857856L
>>> assert(block_hash_int < target)
>>> target - block_hash_int
443556701129704702629742687736175665277878911964584244046365410L
这些整数是如此之大,以至于单独看一个整数几乎不可能知道对比它是容易的还是困难的。但是由于block_hash_int比target整数少一个字符,您可以看到这种情况。当你减去这两个大数时,你得到另一个大数。
这两个方法都是有效的,但是能够查看十六进制字符串比查看整数要好。但实际上,当代码运行时,选择其中一个并没有真正的好处。
计算难度
difficulty最重要的部分是从上问记住difficulty只是target的人类可见的表达。我说过target的整数值是没有意义的,因为很难比较两个巨大的整数值。同样,使用十六进制字符串很难比较两个target。块中的difficulty值是为了使其更容易。
下面,将difficult ty_one_target定义为最容易允许的目标值。要计算另一个块的难度,我们只需将difficult ty_one_target除以使用bits计算出来的target。您将看到,difficult ty_one_target将比任何其他target数字都大,因为其他targets的难度更小。当你用较大的分子除以较小的分母时,你会得到一个大于1的值。
>>> difficulty_one_target = 0x00ffff * 2**(8*(0x1d - 3))
>>> difficulty_one_target
26959535291011309493156476344723991336010898738574164086137773096960L #calculated using
>>> pad_leading_zeros(hex(difficulty_one_target)) #pad_leading_zeros is function defined below
'0x00000000ffff0000000000000000000000000000000000000000000000000000'
>>> calculated_difficulty = difficulty_one_target / float(target) #float() to make it decimal devision
55589.518126868665 #this is the same as the difficulty on the block.
>>> allowed_error = 0.01
>>> assert abs(float(block_difficulty) - calculated_difficulty) <= allowed_error
>>>
请随意回头慢慢地读一遍。我花了很长时间才弄清楚bits、difficulty和target之间的关系。是否需要int、十六进制值或字符串来验证。有很多方法可以做到这一点,希望我已经把它们都列出来了。
如何以及何时更新块难度
比特币工作量证明的最后一个重要部分是,它展示了如何以及何时改变了难度。几乎每一篇关于这个主题的文章都会说,每一个2016个区块,该链都会重新计算所需的新难度。但是他们并没有深入探讨这个话题。这就是我要做的。
第一部分我必须从如何从一个target开始,然后回到bits。get_bits_from_target函数获取一个target参数,计算所设置的最高排名位,并使用它来计算大小。知道了大小后,我们将target一直向下移位,去掉不再需要的零,最后将大小的值放在位的前面,这样就可以保存它了。
>>> bits = '403088579'
>>> hex(int(bits))
'0x1806a4c3'
>>> target = get_target_from_bits(int(bits))
>>> hex(target)
'0x6a4c3000000000000000000000000000000000000000000L'
>>> def get_bits_from_target(target):
... bitlength = target.bit_length() + 1 #look on bitcoin cpp for info
... size = (bitlength + 7) / 8
... value = target >> 8 * (size - 3)
... value |= size << 24 #shift size 24 bits to the left, and taks those on the front of compact
... return value
...
>>> bits = get_bits_from_target(target)
>>> bits
403088579L
>>> hex(bits)
'0x1806a4c3L
它们匹配,所以我们知道代码正确地将target返回到bits。
现在介绍如何为区块链上的实际块集计算下一个块的位。例如这里,我要说我们刚刚收到了块#405215,并且正在挖的块#405216。回看2016个区块,403200将被视为起始区块。
我们有一个从块的bits计算出来的起始target。在接下来的2016个块,我们将使用这个难度。当我们经过第一个块来到第2017个块时,我们计算了从第一个块到第2016个块所花费的秒数。我们用它除以以秒为单位的2016块,用当前target乘以该值,然后计算该target的新bits值。
TARGET_TIMESPAN = 1209600
def change_target(prev_bits, starting_time_secs, prev_time_secs):
old_target = get_target_from_bits(int(prev_bits))
time_span = prev_time_secs - starting_time_secs
time_span_seconds = int(time_span.total_seconds())
new_target = old_target
new_target *= time_span_seconds
new_target /= TARGET_TIMESPAN
return new_target
#starting_block is the initial block on this 2016 block runtime #403200
starting_block_timestamp = '2016-03-18 09:07:48' #timestamp on block
starting_block_time_seconds = datetime.datetime.strptime(starting_block_timestamp, '%Y-%m-%d %H:%M:%S')
#prev_block is the block right before the difficulty conversion #405215
prev_block_bits = '403088579' #bits on block
prev_block_timestamp = '2016-04-01 06:24:09' #timestamp on block
prev_block_time_seconds = datetime.datetime.strptime(prev_block_timestamp, '%Y-%m-%d %H:%M:%S')
calculated_new_target = change_target(prev_block_bits, starting_block_time_seconds, prev_block_time_seconds)
calculated_new_bits = get_bits_from_target(calculated_new_target)
#new_block is the first block of the next block #405216
new_bits = '403085044'
new_target = get_target_from_bits(new_bits)
print hex(calculated_new_target)
print hex(new_target)
print hex(calculated_new_bits)
print hex(int(new_bits))
就得出
Calculated new target: 0x696f4a7b94b94b94b94b94b94b94b94b94b94b94b94b94bL
New target from block: 0x696f4000000000000000000000000000000000000000000L
Calculated new bits: 0x180696f4L
New bits from block: 0x180696f4
计算出的新目标非常具体。但是我们并不关心块的哈希是特定的保证。他们只需要知道前23位。移除掉剩下的部分,向下移位,把移位后的放到前面。
完整代码
我打算复制粘贴我上面写的大量代码,这样你就可以复制粘贴并自己运行它。但是那会占用太多的篇幅。所以这里有一个仓库在这里你可以看到所有的东西。
最后的问题
如果你能走到这一步,那就太棒了!这是我在学习和写作时遇到的一系列问题。如果你还有其他问题,请与我联系,我马上回答。
为什么十六进制值只是字符串?
Why are the hex values only strings?
因为十六进制值只是整数的表示。如果您想查看整数的十六进制值,我们需要一个字符串来查看不同的以16为底的值。看看Python对hex()的定义稍微多一些信息。
Because hex values are only representations of integers. If you’re looking to see the hex value of an integer, we need a string to look at the different base 16 values. Look at the Python definition of hex() slightly more info.
通过字符串比较如何知道’f’ > ‘9’?
How can a string comparison know that ‘f’ > ‘9’?
在内存中,字符存储为unicode值。因此,当比较两个字符时,unicode值较大的字符显示为最大的字符。注意ASCII对于0-127也具有与unicode相同的值。在比较字符串时,它们逐个遍历每个字符,最先获得最大值的字符获胜。
In memory, characters are stored as unicode values. So when you compare two characters, the one with the larger unicode value is shown as being the biggest. Note that ASCII also has the same values as unicode for 0-127. When comparing strings, they go through each character one by one and whichever has the largest value first wins the race.
>>> ord('f')
102
>>> ord('a')
97
>>> ord('b')
98
>>> ord('9')
57
>>> ord('1')
49
>>> ord('2')
50
>>> ord('a')
97
>>> ord('b')
98
>>> ord('f')
102
>>> 'f' > 'a'
True
>>> 'a' > '1'
True
比特币的难度是如何随着时间变化的?
How has Bitcoin difficulty changed over time?
有很多网站都有交互式图表显示了随时间发生的变化;快速的谷歌搜索会找到一个。但是,这里有一张来自比特币实际维基百科页面的图片,展示了这个难度数字是如何随着时间变化的。
There are a bunch of sites that have interactive graphs showing the change over time; quick google will find one. But, here’s the pic from Bitcoin’s actual Wikipedia page that shows how that difficulty number has changed over time.
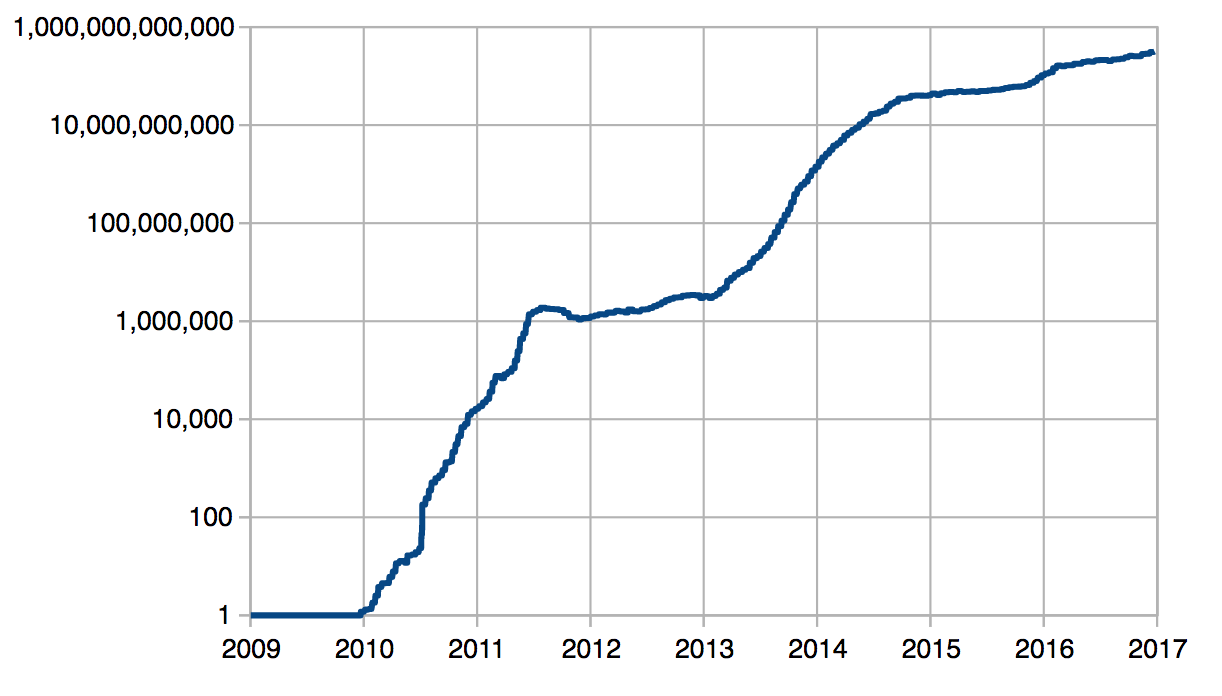 线性很好,中间有一个平点。有人应该做个记录。
线性很好,中间有一个平点。有人应该做个记录。
2011年中期到的2013年初持平的遇到困难是什么?
What’s the deal with mid 2011 to beginning of 2013 difficulty being flat?
看看这个截图来自Bitcoin.com针对2011年到2013年期间。
Look at this screenshot from Bitcoin.com for the time period of 2011 and 2013.

嗯
一枚硬币的价格一路飙升,达到了惊人的29美元一枚,但在2013年初之前,这枚硬币崩溃了,并再次开始飞升。我想说的是,这是一个很好的相关性,矿工们看到了崩溃,并说去它的,停止他们的开采,留下更少的节点试图开采一个新的区块。节点越少,就意味着找到一个有效的散列所需的时间越长,因此我们必须降低难度。
A giant spike in price all the way up to an astonishing $29 a coin that crashed until the beginning of 2013 where it starts flying up again. I’ll go ahead and say there’s a nice correlation there where miners saw the crash and said screw it, stopped their mining, and left fewer nodes trying to mine a new block. Fewer nodes means the longer it takes to find a valid hash so we had to keep difficulty down.
bit值越大,难度越大吗?
Does a larger bit value imply a larger difficulty?
不是的。记住,位值是存储的,所以我们可以把它分成两个数字来计算target。当把它看作一个整数时,它肯定是不可比较的。
Nope. Remember, bit values are stored so we can split it into two numbers used to calculate the target. When looked at as an integer, it’s definitely not comparable.
如果需要示例,请查看上面代码中列出的两个块。比较块0和块32256,你将看到位和难度的相反差异。
If you want examples, look at the couple blocks listed in the code above. Comparing blocks 0 and 32256, you’ll see opposite difference in bits and difficulty.
头部哈希是如何计算的?
How is the header hash calculated?
通过将值打碎在一起。看这里,您将看到更多关于它的信息。
By smashing values together. Take a look here and you’ll see more about it.
我看到有人提到我们只计算2015块的新比特,而不是2016块。那是什么意思?
I see people mentioning we only calculate new bits from 2015 blocks and not 2016. What’s that mean?
在阅读其他文章时,你会经常看到这一点。这意味着如果我们将2016个块的所有块包含在一个集合中,我们将在新的2016个块集合开始之前以时间戳开始,因为这表示节点开始尝试寻找下一个块。
You’ll see that a lot when looking at other posts. What this means is if we included all 2016 blocks in a set, we’d start with the timestamp before the start of a new 2016 set of blocks since that’s says when nodes started trying to find the next block.
当你想要计算块实际2017块的bits数时,这是行不通的。如果我们考虑到第一个2016块挖掘时间,我们就不会知道这一点,因为我们不知道第一批矿工是什么时候开始运营的。
This doesn’t work out when you think of calculating the new bits for actual block 2017. If we took into account how long it took to mine the first 2016, we wouldn’t know that since we didn’t know when we started running the first miners.
为什么不讨论一下找到一个有效的散列需要多少时间?
Why didn’t you talk about how much time it takes to find a valid hash?
那是另一个话题。有一些资料计算如果有一个节点在进行挖掘,但是很难计算出来,除非有更多的节点。当我写jbc困难的部分时,我将有测试来显示时间。
That’s a different topic. There’s some material on calculating that if there’s a single node doing the mining, but that’s tough to figure out unless you have a bigger amount of nodes. When I write the part for jbc’s difficulty, I’ll have tests to show time.
你的推特账号是什么,这样我才能关注你??
What’s your Twitter handle so I can follow you??
如果我只想问你一个问题呢?
What if I only want to ask you a question?
联络是一个很好的方法。只要确保你的电子邮件输入正确;我之前收到过一些邮件,由于那个邮件地址不存在,我无法回复。你也可以自由评论这篇文章。
Contact is a great way to do this. Just make sure you type your email correctly; I’ve gotten some emails before that I couldn’t reply to since that email address didn’t exist. Also feel free to comment on this post as well.
接下来是什么?
What’s next?
第4.2部分关于以太坊工作难度证明!这有点类似,但是目标的计算方法不同。而且,困难改变的时间也是不同的。查看图表显示了我所表达的随着时间的推移难度的变化。
Part 4.2 about the Ethereum proof of work difficulty! It’s somewhat similar, but the target is calculated in a different way. Also, the time when difficulties change is different as well. Check out the chart that show difficulty over time to see what I mean.
在此之后,4.3部分将介绍如何计算jbc的难度。
After that, part 4.3 will be about how I want to calculate difficulty for jbc.